Cause all that matters here is passing the Amazon-Web-Services DOP-C01 exam. Cause all that you need is a high score of DOP-C01 AWS Certified DevOps Engineer- Professional exam. The only one thing you need to do is downloading Examcollection DOP-C01 exam study guides now. We will not let you down with our money-back guarantee.
Free demo questions for Amazon-Web-Services DOP-C01 Exam Dumps Below:
NEW QUESTION 1
You have an Opswork stack defined with Linux instances. You have executed a recipe, but the execution has failed. What is one of the ways that you can use to diagnose what was the reason why the recipe did not execute correctly.
- A. UseAWS Cloudtrail and check the Opswork logs to diagnose the error
- B. UseAWS Config and check the Opswork logs to diagnose the error
- C. Logintotheinstanceandcheckiftherecipewasproperlyconfigured.
- D. Deregisterthe instance and check the EC2 Logs
Answer: C
Explanation:
The AWS Documentation mentions the following
If a recipe fails, the instance will end up in the setup_failed state instead of online. Even though the instance is not online as far as AWS Ops Works Stacks is concerned, the CC2 instance is running and it's often useful to log in to troubleshoot the issue. For example, you can check whether an application or custom
cookbook is correctly installed. The AWS Ops Works Stacks built-in support for SSH and RDP login is
available only for instances in the online state.
For more information on Opswork troubleshooting, please visit the below URL: http://docs.aws.amazon.com/opsworks/latest/userguide/troubleshoot-debug-login.htmI
NEW QUESTION 2
You are a Devops Engineer for your company. You are in charge of an application that uses EC2, ELB and Autoscaling. You have been requested to get the ELB access logs. When you try to access the logs, you can see that nothing has been recorded in S3. Why is this the case?
- A. Youdon't have the necessary access to the logs generated by ELB.
- B. Bydefault ELB access logs are disabled.
- C. TheAutoscaling service is not sending the required logs to ELB
- D. TheEC2 Instances are not sending the required logs to ELB
Answer: B
Explanation:
The AWS Documentation mentions
Access logging is an optional feature of Elastic Load Balancing that is disabled by default. After you enable access logging for your load balancer. Clastic Load
Balancing captures the logs and stores them in the Amazon S3 bucket that you specify. You can disable access logging at any time.
For more information on L~LB access logs please see the below link:
• http://docs.aws.amazon.com/elasticloadbalancing/latest/classic/access-log-collection.html
NEW QUESTION 3
You are deciding on a deployment mechanism for your application. Which of the following deployment mechanisms provides the fastest rollback after failure.
- A. Rolling-Immutable
- B. Canary
- C. Rolling-Mutable
- D. Blue/Green
Answer: D
Explanation:
In Blue Green Deployments, you will always have the previous version of your application available.
So anytime there is an issue with a new deployment, you can just quickly switch back to the older version of your application.
For more information on Blue Green Deployments, please refer to the below link: https://docs.cloudfoundry.org/devguide/deploy-apps/blue-green.html
NEW QUESTION 4
There is a requirement for an application hosted on a VPC to access the On-premise LDAP server. The VPC and the On-premise location are connected via an I PSec VPN. Which of the below are the right options for the application to authenticate each user. Choose 2 answers from the options below
- A. Develop an identity broker that authenticates against 1AM security Token service to assume a 1AM role in order to get temporary AWS security credentials The application calls the identity broker to get AWS temporary security credentials.
- B. The application authenticates against LDAP and retrieves the name of an 1AM role associated with the use
- C. The application then calls the 1AM Security Token Service to assume that 1AM rol
- D. The application can use the temporary credentials to access any AWS resources.
- E. Develop an identity broker that authenticates against LDAP and then calls 1AM Security Token Service to get 1AM federated user credential
- F. The application calls the identity broker to get 1AM federated user credentials with access to the appropriate AWS service.
- G. The application authenticates against LDAP the application then calls the AWS identity and Access Management (1AM) Security service to log in to 1AM using the LDAP credentials the application can use the 1AM temporary credentials to access the appropriate AWS service.
Answer: BC
Explanation:
When you have the need for an in-premise environment to work with a cloud environment, you would normally have 2 artefacts for authentication purposes
• An identity store - So this is the on-premise store such as Active Directory which stores all the information for the user's and the groups they below to.
• An identity broker - This is used as an intermediate agent between the on-premise location and the cloud environment. In Windows you have a system known as Active Directory Federation services to provide this facility.
Hence in the above case, you need to have an identity broker which can work with the identity store and the Security Token service in aws. An example diagram of how this works from the aws documentation is given below.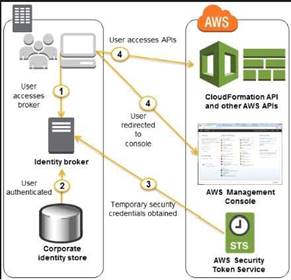
For more information on federated access, please visit the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_common-scenarios_federated- users.htm I
NEW QUESTION 5
When creating an Elastic Beanstalk environment using the Wizard, what are the 3 configuration options presented to you
- A. Choosingthetypeof Environment- Web or Worker environment
- B. Choosingtheplatformtype-Nodejs,IIS,etc
- C. Choosing the type of Notification - SNS or SQS
- D. Choosing whether you want a highly available environment or not
Answer: ABD
Explanation:
The below screens are what are presented to you when creating an Elastic Beanstalk environment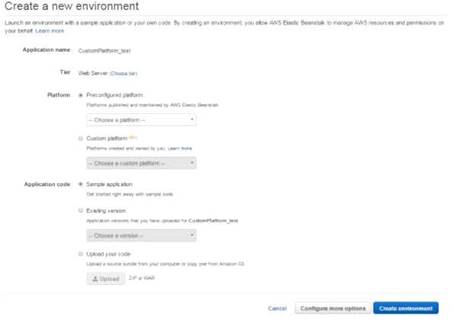
The high availability preset includes a load balancer; the low cost preset does not For more information on the configuration settings, please refer to the below link: http://docs.aws.amazon.com/elasticbeanstalk/latest/dg/environments-create-wizard.html
NEW QUESTION 6
Your company has an application hosted in AWS which makes use of DynamoDB. There is a requirement from the IT security department to ensure that all source IP addresses which make calls to the DynamoDB tables are recorded. Which of the following services can be used to ensure this requirement is fulfilled.
- A. AWSCode Commit
- B. AWSCode Pipeline
- C. AWSCIoudTrail
- D. AWSCIoudwatch
Answer: C
Explanation:
The AWS Documentation mentions the following
DynamoDB is integrated with CloudTrail, a service that captures low-level API requests made by or
on behalf of DynamoDB in your AWS account and delivers the log files to an Amazon S3 bucket that you specify. CloudTrail captures calls made from the DynamoDB console or from the DynamoDB low-level API. Using the information collected by CloudTrail, you can determine what request was made to DynamoDB, the source IP address from which the request was made, who made the request, when it was made, and so on.
For more information on DynamoDB and Cloudtrail, please refer to the below link:
• http://docs.aws.amazon.com/amazondynamodb/latest/developerguide/logging-using- cloudtrail.htmI
NEW QUESTION 7
What is the amount of time that Opswork stacks services waits for a response from an underlying instance before deeming it as a failed instance?
- A. Iminute.
- B. 5minutes.
- C. 20minutes.
- D. 60minutes
Answer: B
Explanation:
The AWS Documentation mentions
Every instance has an AWS OpsWorks Stacks agent that communicates regularly with the service. AWS OpsWorks Stacks uses that communication to monitor instance health. If an agent does not communicate with the service for more than approximately five minutes, AWS OpsWorks Stacks considers the instance to have failed.
For more information on the Auto healing feature, please visit the below URL: http://docs.aws.amazon.com/opsworks/latest/userguide/workinginstances-auto healing.htmI
NEW QUESTION 8
You have a set of EC2 Instances running behind an ELB. These EC2 Instances are launched via an Autoscaling Group. There is a requirement to ensure that the logs from the server are stored in a durable storage layer. This is so that log data can be analyzed by staff in the future. Which of the following steps can be implemented to ensure this requirement is fulfilled. Choose 2 answers from the options given below
- A. Onthe web servers, create a scheduled task that executes a script to rotate andtransmit the logs to an Amazon S3 bucke
- B. */
- C. UseAWS Data Pipeline to move log data from the Amazon S3 bucket to Amazon Redshiftin order to process and run reports V
- D. Onthe web servers, create a scheduled task that executes a script to rotate andtransmit the logs to Amazon Glacier.
- E. UseAWS Data Pipeline to move log data from the Amazon S3 bucket to Amazon SQS inorder to process and run reports
Answer: AB
Explanation:
Amazon S3 is the perfect option for durable storage. The AWS Documentation mentions the following on S3 Storage Amazon Simple Storage Service (Amazon S3) makes it simple and practical to collect, store, and analyze data - regardless of format - all at massive scale. S3 is object storage built to store and retrieve any amount of data from anywhere - web sites and mobile apps, corporate applications, and data from loT sensors or devices.
For more information on Amazon S3, please refer to the below URL:
• https://aws.amazon.com/s3/
Amazon Redshift is a fast, fully managed data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing Business Intelligence (Bl) tools. It allows you to run complex analytic queries against petabytes of structured data, using sophisticated query optimization, columnar storage on high-performance local disks, and massively parallel query execution. Most results come back in seconds. For more information on Amazon Redshift, please refer to the below URL:
• https://aws.amazon.com/redshift/
NEW QUESTION 9
Which of the following can be configured as targets for Cloudwatch Events. Choose 3 answers from
the options given below
- A. AmazonEC2 Instances
- B. AWSLambda Functions
- C. AmazonCodeCommit
- D. AmazonECS Tasks
Answer: ABD
Explanation:
The AWS Documentation mentions the below
You can configure the following AWS sen/ices as targets for Cloud Watch Events
For more information on Cloudwatch events please see the below link:
• http://docs.aws.amazon.com/AmazonCloudWatch/latest/events/WhatlsCloudWatchEvents.htmI
NEW QUESTION 10
Which of the below services can be used to deploy application code content stored in Amazon S3 buckets, GitHub repositories, or Bitbucket repositories
- A. CodeCommit
- B. CodeDeploy
- C. S3Lifecycles
- D. Route53
Answer: B
Explanation:
The AWS documentation mentions
AWS CodeDeploy is a deployment service that automates application deployments to Amazon EC2 instances or on-premises instances in your own facility.
For more information on Code Deploy please refer to the below link:
• http://docs.ws.amazon.com/codedeploy/latest/userguide/welcome.html
NEW QUESTION 11
You have a requirement to host a cluster of NoSQL databases. There is an expectation that there will be a lot of I/O on these databases. Which EBS volume type is best for high performance NoSQL cluster deployments?
- A. io1
- B. gp1
- C. standard
- D. gp2
Answer: A
Explanation:
Provisioned IOPS SSD should be used for critical business applications that require sustained IOPS performance, or more than 10,000 IOPS or 160 MiB/s of throughput per volume
This is ideal for Large database workloads, such as:
• MongoDB
• Cassandra
• MicrosoftSQL Server
• MySQL
• PostgreSQL
• Oracle
For more information on the various CBS Volume Types, please refer to the below link:
• http://docs.aws.amazon.com/AWSCC2/latest/UserGuide/ CBSVolumeTvpes.html
NEW QUESTION 12
You're building a mobile application game. The application needs permissions for each user to communicate and store data in DynamoDB tables. What is the best method for granting each mobile device that installs your application to access DynamoDB tables for storage when required? Choose the correct answer from the options below
- A. During the install and game configuration process, have each user create an 1AM credential and assign the 1AM user to a group with proper permissions to communicate with DynamoDB.
- B. Create an 1AM group that only gives access to your application and to the DynamoDB table
- C. Then, when writing to DynamoDB, simply include the unique device ID to associate the data with that specific user.
- D. Create an 1AM role with the proper permission policy to communicate with the DynamoDB tabl
- E. Use web identity federation, which assumes the 1AM role using AssumeRoleWithWebldentity, when the user signs in, granting temporary security credentials using STS.
- F. Create an Active Directory server and an AD user for each mobile application use
- G. When the user signs in to the AD sign-on, allow the AD server to federate using SAML 2.0 to 1AM and assign a role to the AD user which is the assumed with AssumeRoleWithSAML
Answer: C
Explanation:
Answer - C
For access to any AWS service, the ideal approach for any application is to use Roles. This is the first preference.
For more information on 1AM policies please refer to the below link:
http://docs.aws.amazon.com/IAM/latest/UserGuide/access_policies.html
Next for any web application, you need to use web identity federation. Hence option D is the right option. This along with the usage of roles is highly stressed in the aws documentation.
The AWS documentation mentions the following
When developing a web application it is recommend not to embed or distribute long-term AWS credentials with apps that a user downloads to a device, even in an encrypted store. Instead, build your app so that it requests temporary AWS security credentials dynamically when needed using web identity federation. The
supplied temporary credentials map to an AWS role that has only the permissions needed to perform the tasks required by the mobile app.
For more information on web identity federation please refer to the below link: http://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_providers_oidc.html
NEW QUESTION 13
Which of the following features of the Autoscaling Group ensures that additional instances are neither launched or terminated before the previous scaling activity takes effect
- A. Termination policy
- B. Cool down period
- C. Ramp up period
- D. Creation policy
Answer: B
Explanation:
The AWS documentation mentions
The Auto Scaling cooldown period is a configurable setting for your Auto Scaling group that helps to ensure that Auto Scaling doesn't launch or terminate additional
instances before the previous scaling activity takes effect. After the Auto Scaling group dynamically scales using a simple scaling policy. Auto Scaling waits for the
cooldown period to complete before resuming scaling activities. When you manually scale your Auto Scaling group, the default is not to wait for the cooldown period,
but you can override the default and honor the cooldown period. If an instance becomes unhealthy.
Auto Scaling does not wait for the cooldown period to complete before replacing the unhealthy instance
For more information on the Cool down period, please refer to the below URL:
• http://docs.ws.amazon.com/autoscaling/latest/userguide/Cooldown.htmI
NEW QUESTION 14
Your development team is using access keys to develop an application that has access to S3 and DynamoDB. A new security policy has outlined that the credentials should not be older than 2 months, and should be rotated. How can you achieve this
- A. Use the application to rotate the keys in every 2 months via the SDK
- B. Use a script which will query the date the keys are create
- C. If older than 2 months, delete them and recreate new keys
- D. Delete the user associated with the keys after every 2 month
- E. Then recreate the user again.D- Delete the I AM Role associated with the keys after every 2 month
- F. Then recreate the I AM Roleagain.
Answer: B
Explanation:
One can use the CLI command list-access-keys to get the access keys. This command also returns the "CreateDate" of the keys. If the CreateDate is older than 2 months, then the keys can be deleted.
The Returns list-access-keys CLI command returns information about the access key IDs associated with the specified I AM user. If there are none, the action returns
an empty list.
For more information on the CLI command, please refer to the below link: http://docs.aws.amazon.com/cli/latest/reference/iam/list-access-keys.html
NEW QUESTION 15
Which of the below is not a lifecycle event in Opswork?
- A. Setup
- B. Uninstall
- C. Configure
- D. Shutdown
Answer: B
Explanation:
Below are the Lifecycle events of Opsstack
1) Setup - This event occurs after a started instance has finished booting.
2) Configure - This event occurs on all of the stack's instances when one of the following occurs:
a) An instance enters or leaves the online state.
b) You associate an Clastic IP address with an instance or disassociate one from an instance.
c) You attach an Clastic Load Balancing load balancer to a layer, or detach one from a layer.
3) Deploy - This event occurs when you run a Deploy command, typically to deploy an application to a set of application server instances.
4) Undeploy - This event occurs when you delete an app or run an Undeploy command to remove an app from a set of application server instances.
5) Shutdown - This event occurs after you direct AWS Ops Works Stacks to shut an instance down but before the associated Amazon CC2 instance is actually terminated
For more information on Opswork lifecycle events, please visit the below URL:
• http://docs.aws.amazon.com/opsworks/latest/userguide/workingcookbook-events.htm I
NEW QUESTION 16
You need to create an audit log of all changes to customer banking data. You use DynamoDB to store this customer banking data. It's important not to lose any information due to server failures. What is an elegant way to accomplish this?
- A. Use a DynamoDB StreamSpecification and stream all changes to AWS Lambd
- B. Log the changes to AWS CloudWatch Logs, removing sensitive information before logging.
- C. Before writing to DynamoDB, do a pre-write acknoledgment to disk on the application server, removing sensitive information before loggin
- D. Periodically rotate these log files into S3.
- E. Use a DynamoDB StreamSpecification and periodically flush to an EC2 instance store, removing sensitive information before putting the object
- F. Periodically flush these batches to S3.
- G. Before writing to DynamoDB, do a pre-write acknoledgment to disk on the application server, removing sensitive information before loggin
- H. Periodically pipe these files into CloudWatch Logs.
Answer: A
Explanation:
You can use Lambda functions as triggers for your Amazon DynamoDB table. Triggers are custom actions you take in response to updates made to the DynamoDB table. To create a trigger, first you enable Amazon DynamoDB Streams for your table. Then, you write a Lambda function to process the updates published to the stream.
For more information on DynamoDB with Lambda, please visit the below URL: http://docs.aws.a mazon.com/lambda/latest/dg/with-ddb.html
NEW QUESTION 17
You currently have an application with an Auto Scalinggroup with an Elastic Load Balancer configured in AWS. After deployment users are complaining of slow response time for your application. Which of the following can be used as a start to diagnose the issue
- A. Use Cloudwatch to monitor the HealthyHostCount metric
- B. Use Cloudwatch to monitor the ELB latency
- C. Use Cloudwatch to monitor the CPU Utilization
- D. Use Cloudwatch to monitor the Memory Utilization
Answer: B
Explanation:
High latency on the ELB side can be caused by several factors, such as:
• Network connectivity
• ELB configuration
• Backend web application server issues
For more information on ELB latency, please refer to the below link:
• https://aws.amazon.com/premiumsupport/knowledge-center/elb-latency-troubleshooting/
NEW QUESTION 18
Which of these is not an instrinsic function in AWS CloudFormation?
- A. Fn::Equals
- B. Fn::lf
- C. Fn::Not
- D. Fn::Parse
Answer: D
Explanation:
You can use intrinsic functions, such as Fn::lf, Fn::Cquals, and Fn::Not, to conditionally create stack resources. These conditions are evaluated based on input parameters that you declare when you create or update a stack. After you define all your conditions, you can associate them with resources or resource properties in the Resources and Outputs sections of a template.
For more information on Cloud Formation template functions, please refer to the URL:
• http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/intrinsic-function- reference.html and
• http://docs.aws.a mazon.com/AWSCIoudFormation/latest/UserGuide/intri nsic-function- reference-conditions.html
NEW QUESTION 19
You are working for a startup company that is building an application that receives large amounts of data. Unfortunately, current funding has left the start-up short on cash, cannot afford to purchase thousands of dollars of storage hardware, and has opted to use AWS. Which services would you implement in order to store a virtually unlimited amount of data without any effort to scale when demand unexpectedly increases? Choose the correct answer from the options below
- A. AmazonS3, because it provides unlimited amounts of storage data, scales automatically highlyavailable, and durable
- B. AmazonGlacier, to keep costs low for storage and scale infinitely
- C. Amazonlmport/Export, because Amazon assists in migrating large amounts of data toAmazon S3
- D. AmazonEC2, because EBS volumes can scale to hold any amount of data and, when usedwith Auto Scaling, can be designed for fault tolerance and high availability
Answer: A
Explanation:
The best option is to use S3 because you can host a large amount of data in S3 and is the best storage option provided by AWS.
For more information on S3, please refer to the below link:
• http://docs.aws.a mazon.com/AmazonS3/latest/dev/We lcome.htmI
NEW QUESTION 20
You are planning on using AWS Code Deploy in your AWS environment. Which of the below features of AWS Code Deploy can be used to Specify scripts to be run on each instance at various stages of the deployment process
- A. AppSpecfile
- B. CodeDeployfile
- C. Configfile
- D. Deploy file
Answer: A
Explanation:
The AWS Documentation mentions the following on AWS Code Deploy
An application specification file (AppSpec file), which is unique to AWS CodeDeploy, is a YAML- formatted file used to:
Map the source files in your application revision to their destinations on the instance. Specify custom permissions for deployed files.
Specify scripts to be run on each instance at various stages of the deployment process. For more information on AWS CodeDeploy, please refer to the URL: http://docs.aws.amazon.com/codedeploy/latest/userguide/application-specification-files.htmI
NEW QUESTION 21
You have an ELB setup in AWS with EC2 instances running behind it. You have been requested to monitor the incoming connections to the ELB. Which of the below options can suffice this requirement?
- A. UseAWSCIoudTrail with your load balancer
- B. Enable access logs on the load balancer
- C. Use a CloudWatch Logs Agent
- D. Create a custom metric CloudWatch filter on your load balancer
Answer: B
Explanation:
Clastic Load Balancing provides access logs that capture detailed information about requests sent to your load balancer. Cach log contains information such as the
time the request was received, the client's IP address, latencies, request paths, and server responses.
You can use these access logs to analyze traffic patterns and to troubleshoot issues.
Option A is invalid because this service will monitor all AWS services Option C and D are invalid since CLB already provides a logging feature.
For more information on ELB access logs, please refer to the below document link: from AWS http://docs.aws.amazon.com/elasticloadbalancing/latest/classic/access-log-collection.html
NEW QUESTION 22
The operations team and the development team want a single place to view both operating system and application logs. How should you implement this using A WS services? Choose two from the options below
- A. Using AWS CloudFormation, create a Cloud Watch Logs LogGroup and send the operating system and application logs of interest using the Cloud Watch Logs Agent.
- B. Using AWS CloudFormation and configuration management, set up remote logging to send events via UDP packets to CloudTrail.
- C. Using configuration management, set up remote logging to send events to Amazon Kinesis and insert these into Amazon CloudSearch or Amazon Redshift, depending on available analytic tools.
- D. Using AWS CloudFormation, merge the application logs with the operating system logs, and use 1AM Roles to allow both teams to have access to view console output from Amazon EC2.
Answer: AC
Explanation:
Option B is invalid because Cloudtrail is not designed specifically to take in UDP packets
Option D is invalid because there are already Cloudwatch logs available, so there is no need to have specific logs designed for this.
You can use Amazon CloudWatch Logs to monitor, store, and access your log files from Amazon Elastic Compute Cloud (Amazon L~C2) instances, AWS CloudTrail,
and other sources. You can then retrieve the associated log data from CloudWatch Logs. For more information on Cloudwatch logs please refer to the below link:
http://docs^ws.amazon.com/AmazonCloudWatch/latest/logs/WhatlsCloudWatchLogs.html You can the use Kinesis to process those logs
For more information on Amazon Kinesis please refer to the below link: http://docs.aws.a mazon.com/streams/latest/dev/introduction.html
NEW QUESTION 23
Your company is using an Autoscaling Group to scale out and scale in instances. There is an expectation of a peak in traffic every Monday at 8am. The traffic is then expected to come down before the weekend on Friday 5pm. How should you configure Autoscaling in this?
- A. Createdynamic scaling policies to scale up on Monday and scale down on Friday
- B. Create a scheduled policy to scale up on Fridayand scale down on Monday
- C. CreateascheduledpolicytoscaleuponMondayandscaledownonFriday
- D. Manuallyadd instances to the Autoscaling Group on Monday and remove them on Friday
Answer: C
Explanation:
The AWS Documentation mentions the following for Scheduled scaling
Scaling based on a schedule allows you to scale your application in response to predictable load changes. For example, every week the traffic to your web application starts to increase on Wednesday, remains high on Thursday, and starts to decrease on Friday. You can plan your scaling activities based on the predictable traffic patterns of your web application.
For more information on scheduled scaling for Autoscaling, please visit the below URL
• http://docs.aws.amazon.com/autoscaling/latest/userguide/sched ule_time.htm I
NEW QUESTION 24
You are using CloudFormation to launch an EC2 instance and then configure an application after the instance is launched. You need the stack creation of the ELB and Auto Scaling to wait until the EC2 instance is launched and configured properly. How do you do this?
- A. It is not possible for the stack creation to wait until one service is created and launched
- B. Use the WaitCondition resource to hold the creation of the other dependent resources
- C. Use a CreationPolicy to wait for the creation of the other dependent resources >/
- D. Use the HoldCondition resource to hold the creation of the other dependent resources
Answer: C
Explanation:
When you provision an Amazon EC2 instance in an AWS Cloud Formation stack, you might specify additional actions to configure the instance, such as install software packages or bootstrap applications. Normally, CloudFormation proceeds with stack creation after the instance has been successfully created. However, you can use a Creation Pol icy so that CloudFormation proceeds with stack creation only after your configuration actions are done. That way you'll know your applications are ready to go after stack creation succeeds.
A Creation Policy instructs CloudFormation to wait on an instance until CloudFormation receives the specified number of signals
Option A is invalid because this is possible
Option B is invalid because this is used make AWS CloudFormation pause the creation of a stack and wait for a signal before it continues to create the stack
For more information on this, please visit the below URL:
• https://aws.amazon.com/blogs/devops/use-a-creationpolicy-to-wait-for-on-instance- configurations/
NEW QUESTION 25
You are in charge of designing Cloudformation templates for your company. One of the key requirements is to ensure that if a Cloudformation stack is deleted, a snapshot of the relational database is created which is part of the stack. How can you achieve this in the best possible way?
- A. Create a snapshot of the relational database beforehand so that when the cloudformation stack is deleted, the snapshot of the database will be present.
- B. Use the Update policy of the cloudformation template to ensure a snapshot is created of the relational database.
- C. Use the Deletion policy of the cloudformation template to ensure a snapshot is created of the relational database.
- D. Create a new cloudformation template to create a snapshot of the relational database.
Answer: C
Explanation:
The AWS documentation mentions the following
With the Deletion Policy attribute you can preserve or (in some cases) backup a resource when its stack is deleted. You specify a DeletionPolicy attribute for each resource that you want to control. If a resource has no DeletionPolicy attribute, AWS Cloud Formation deletes the resource by default. Note that this capability also applies to update operations that lead to resources being removed.
For more information on the Deletion policy, please visit the below URL: http://docs.aws.amazon.com/AWSCIoudFormation/latest/UserGuide/aws-attri bute- deletionpolicy.html
NEW QUESTION 26
......
100% Valid and Newest Version DOP-C01 Questions & Answers shared by 2passeasy, Get Full Dumps HERE: https://www.2passeasy.com/dumps/DOP-C01/ (New 116 Q&As)